
Model Evaluation
Confusion Matrix, ROC Curve,AUC value的意义
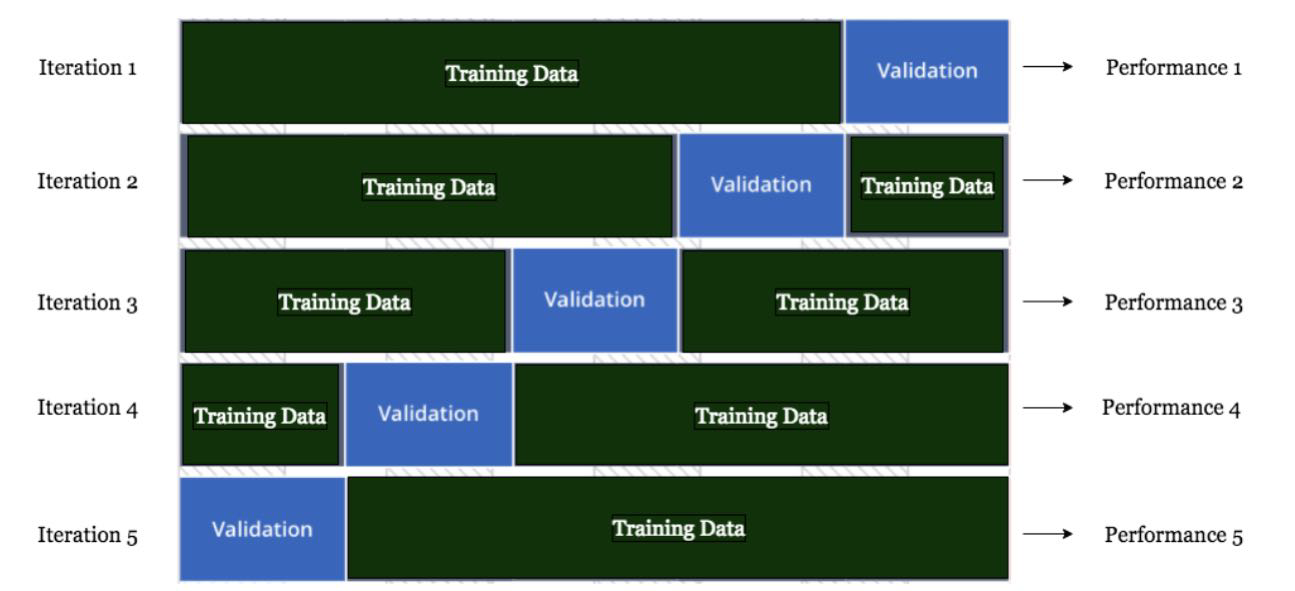
Cross Validation
帮助判断assumption和所处理的data是否吻合,如果performance好( ),说明的是模型本身选择的好(比如 证明的是linear model合格)。
此外,cross validation也可以用来调超参数,比如regularization里的lambda、knn里的k值
Confusion Matrix
这里我们讨论binary classification problem
"True Positive"
第一个词代表你说的是对是错,第二个是你说的是什么。
一般在统计中,positive是我们感兴趣的那个,比如 有癌症、有罪、是垃圾邮件
precision=TP/(TP+FP),表示被分为正例的示例中实际为正例的比例。找到的有病里,实际有多少有病。
recall=sensitivity=TP/(TP+FN)=TP/P,覆盖面的度量,度量有多个正例被分为正例。所有有病的人有多少被找到。
如果非要牺牲一个保留另一个,我们该牺牲谁保留谁?
spam email detection: precision高是基本要求,尽可能提高recall
disease/ anomaly detection: recall高是基本要求,尽可能提高precision
accuracy=(TP+TN)/(P+N)
F1=precision+recall2×precision×recall
面试考点:
(1) 公司说一堆,然后给出“precision是xx“,这个产品要不要launch
回答 interesting. How about the recall?
(2) 公司说一堆,问如何制定metric?
回答 In this case, we need to evaluate which factor is more important. Precision/ Recall
(3) 如果不改变模型,该如何提高precision?
除了model本身之外,注意threshold,阈值也会影响precision、recall!比如我们特地把threshold从0.5提高到0.9, 那么precision就会提高,但是recall就降低了。我们以牺牲recall作为代价提高了precision。
在计算时,其实是人为引入threshold,以这个threshold计算概率,来给出Precision、Recall、F1。所以其实用这些数值来衡量model的水平不够客观。如果我们只想知道分类器的水平,只看precision和recall不是很好的metric。
这时,引入ROC。
ROC Curve

思想:直接定义一个metric,直观给出分类器的概率(与threshold无关的metric,来定义classifier performance)。无关,意味着threshold可以取到任意值,都能评价到model的好坏。通过改变threshold画图得到ROC Curve. 来自EE的统计信号处理的思想,Fourier变换。
y: True Positive Rate = recall = sensitivity
x: False Positive Rate
在不变的testing data上的performance,此时模型确定,testing data确定,所以evaluation的结果也是确定的值。但是之所以会有一条线,是因为threshold变化。
记四个点
(0,0),我们定义的threshold是1,所有的都认为是negative,eg 只有当肿瘤大小非常大时才认为它有病,所以所有人都被判断为没病。注意这和分类器的表现没关系,只是threshold高。也正因为如此,false positive rate=0,everything is negative. True positive rate也是零
(1,1),我们定义的threshold是0,所有的都认为是positive,eg 每个人都认为没病
(0,1),最理想情况,没有false positive,所有positive都找对了
Equal Error Rate means FPR=FNR
既然越凸越好,可以定义AUC来描述它有多凸(AUC的面积有多大),以此定量来表示。
潜在面试题:AUC的值域是[0.5,1], 可以被理解为概率。那么,AUC的值是0.6的话,它的物理意义是什么?这个概率的物理意义是什么?
The probability that a randomly-chosen positive example is ranked higher than a randomly chosen negative example.
Example:
A B C D E
Truth 0 0 1 0 1
Predict 0.2 0.3 0.6 0.1 0.7
排队, 0 D A B C E 1
来个人,切一刀,eg D A | B C E 1 如果天赋好一点的人切对了,切在了 D A B | C E 1
但要记得切错不是model的锅,因为AUC的定义是:任意一个数据把positive排在negative后面的概率 所以此时 AUC=1 所有的negative其实都在positive的前面
此时如果我们换一个model排队,0.2 0.3 0.1 0.1 0.7 此时 0 C D A B E 1 不管怎么切都不可能对了,因为这是model自己的问题,此时的AUC<1
还有一个理解误区,ROC curve和数据点的个数有关,点少了画不出来。不!ROC curve 一定可以画得出来,和testing dataset有多大没关系,因为它是通过调整threshold画的,即使只有5个点,但我们依然可以给10000个threshold.
那么有了它,怎么选threshold?——一般0.5上下随便选,或者根据use case来调整,也有人选在Equal Error Rate,但其实没啥意义,只是单纯在展示自己知识渊博,换句话就是炫技。
Last updated